I’ve had a set of blog posts stewing in my brain for a while. Steve Nelson, last year, helped me out with a Regular Expression (Regex) and I made it a point to practice my Regex skills more.
This series will show how to use Regular Expressions in Eclipse and we’ll learn some helpful tips along the way.
This series is for you if you are the kind of developer that reads Ben Nadel’s blog posts containing Regular Expressions, and has no idea what the heck he is talking about. Seriously Ben, this is unintelligible to us mere mortals:
<cfset blogContent = reReplace(
blogContent,
“</?\w+(\s*[\w:]+\s*=\s*(“”[^””]*””|'[^’]*’))*\s*/?>”,
” “,
“all”
) />
(It looks like a catnip crazed kitty went for a prance on a keyboard, doesn’t it?)
Enough guffaws and such. On with the learning.
Editors Note:
Simply reading these blog posts aren’t going to help you. Open eclipse, and copy/paste this stuff into your find/replace dialog. You’ll learn more, or your money back!
So, firstly we need a use case. Let’s pretend we are going through some old code and looking to add HTMLEditFormat around some arguments so that the forms won’t break if there are quotes.
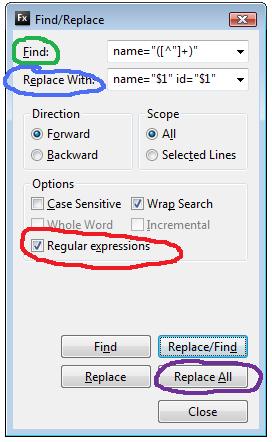
Assume this set of declarations:
<input name="fred" value="willy" /> <input name="bill" value="mickey" /> <input name="erin" value="harry" /> <input name="baz" value="pissette" />
What we want, is to turn: <input name=”fred” value=”willy” />
into: <input name=”fred” id=”fred” value=”willy” />
Normally, this would be a forearm/wrist fatiguing flail on the keyboard, furiously cutting/pasting and generally flapping about. Not so with Regular Expressions. A Regex is a pattern matcher, and it can do stuff.
We can see our code is repetitive and the pattern we want is: make a new attribute called ‘id’ and populate it with the value from the attribute ‘name’… which is what we’d do over and over via cut/paste/etc.
We can define this pattern in the gobbledegook defining a regular expression, of course, else I’d be writing this post about Cute LOLCats, not Cute Regexes., wouldn’t I? We’ll go through the exercise, then look at why it worked.
In Eclipse, perform the following:
- Open a new file and paste the above set of declarations: ( remember the chunk above starting with <input name=”fred” value=”willy” />…)
- Open the find dialogue (I use CTRL+F) and make sure the Regular Expression option is ticked
- Enter the following in the Find: Input name=”([^”]+)”
- Enter the following in the Replace: Input name=”$1″ id=”$1″
- Press Find and make sure the pattern matches what we want
- Lastly, press Replace All
You Should Have This:
<input name="fred" id="fred" value="willy" /> <input name="bill" id="bill" value="mickey" /> <input name="erin" id="erin" value="harry" /> <input name="baz" id="baz" value="pisser" />
(if not, you missed a step. Look at the image and compare with what you have in your Find/Replace dialog. Make sure there is no extra whitespace in the find expression)
Blamo! Your code is now properly sorted out with the new ID attribute and you didn’t even get carpal tunnel syndrome! Let’s decode the code, shall we?
Here is the find portion of the regular expression: name=”([^”])+”
- name=” The first character chunk is the word ‘name’ followed by an equals sign, then a double quote. These are all literals and need no escaping.
- ( The next character is an open parenthesis. This defines the beginning of a group. Remember, we want to use the value of the name attribute to populate the name of the ID attribute.
- [^”]+ The next chunk defines any character that is not a double quote. Note it starts with an open bracket, used to define a set. Inside the open bracket is a carat. This means it is opposite day and our set should NOT INCLUDE the whatever follows. What follows is a double quote, because the value of an attribute is inside the boundaries of the double quotes. We close this character set with the close bracket, then a plus symbol because a plus symbol defines 1 or more of the previous character in the expression. We definitely want more than one character before the closing double quote, else we don’t want a match.
- ) Lastly, we have the closing parenthesis defining the end of our group and another double quote symbolizing the end of our matching boundary.
All of that defines boundaries for a character walking regular expression gnome to take the stuff inside the attribute and hold on to it.
Then in the Replace section, we used: name=”$1″ id=”$1″
- The ‘name’ and ‘id’ attributes, along with both equal signs and both sets of double quotes are all litteral, no escaping needed.
- The $1 refers to the group we defined in the Find input and we use it twice. $n is called a backreference.
So in plain English, we asked the regular expression find/replace gnome to: Take the stuff inside the ‘name’ attribute, and stick it back in the ‘name’ attribute and also inside of a new ‘id’ attribute.
I’m sure you can agree this was much easier than a copy/paste extravaganza… Stay tuned for part two…